Navigating CryspIQ®
Learn how to easily move through the CryspIQ® Application—understand the layout, explore core modules, and discover how to access insights quickly and efficiently.
User Module
The User Module enables you to manage the users that have been assigned licenses within CryspIQ®. Your licensing model is based of the number of users you have registered in Microsoft Azure AD to use CryspIQ®.

Different types of users will be required for your organisations. This is completely separate to Data Access which is covered off in the Security section. You can have the following types of users, which can perform difference application functions:
- Company Administrator (manages Company Details, Licence and Users)
- Data Administrator (manages source connections, creates mappings and assigns Security)
- Data Steward (manages Data Quality issues)
- Normal Users (includes anyone building queries or using data from CryspIQ®).
- Application Users (system to system communication using APIs)
Licensed Users
You have the ability to:
- Create and add new users up to the licence limit.
- Edit and update your users
- Delete users, which removes users from your user license count.
Application Roles
Assign application level roles to each user, the different types of users are outlined in the table below:
| User Type | Properties |
|---|---|
| Company Administrator |
|
| Data Administrator |
|
| Data Steward |
|
| Normal Users |
|
| Application Users |
|
Licensing
User allocations available in each version are outlined below:
- Up to 5 users (combination of administrator and user Role types) are allowed in the Lite version.
- Up to 20 users (combination of administrator and user Role types) are allowed in the Pro version.
- Unlimited users (combination of administrator, user and application Role types) in the Enterprise version.
Security Module
The Security Module enables you to manage the security and control access to your data. CryspIQ® integrates seamlessly with your existing Microsoft Entra ID and enables you to manage the security of your data to a granular level. All data is secured using Microsoft Entra ID security groups. Users are assigned to one or many different Security Groups depending on what they should be allowed to see. Each security group is assigned access to your different data elements. Users can see what they have access to via the Data Catalogue screen.
 Key Benefits:
Key Benefits:- Security managed in a single place.
- Applied on a single database schema.
- Simplified maintenance processes.
Ensure that all your data is secured and manage your compliance with:
- Privacy laws in your Country.
- Sarbanes-Oxley Act of 2002 (commonly referred to as “SOX”).
- Security of Critical Infrastructure Act 2018 (SOCI).
- Setting up EntraID Security Groups
- Applying security at columnar level.
- Applying security at a field level.
Data Access Levels
Manage your data access control. You have the ability to:
- Create and add new groups and connect to the AD Group.
- Assign to EntraID security groups.
- Update your roles and connections to EntraID security groups.
- Delete roles and connections to EntraID security groups.
Object Security
Secure your data at a field level for identified fact types. Data is locked by default, so noone can access, use or view it. It requires the Data Administrator to assign it the relevant security groups before it can be used.
Contextual Security
Secure your data at a columnar level. Data is locked by default, so noone can access, use or view it. It requires the Data Administrator to assign it the relevant security groups before it can be used.
Licensing
All versions have access to the same data security features.
Sources Module
The Sources Module enables you to manage the different source systems and source messages that you wish to load into CryspIQ®.
As there are no constraints on the number of source messages, you have no restrictions around how much data you can load.
 Key Benefits:
Key Benefits:- Unlimited source messages.
- Load and store all your data with context.
- Build up the single source of truth for your organisation.
All licenses have direct access to the existing source system plug-in library. These plug-ins contain:
- Pre-built source system extractors,
- Source message structures,
- Predefined maps into CryspIQ®.
- Re-use an existing system plug-in and adjust it to fit your needs.
- Build your own source system plug-in and add it to the global library.
Upload Data File
Enables the Data Administrator to upload a source system data object in xml or csv format.
Messages
Manage your source message structures (schemas) from the source systems. You have the ability to:
- Add a new source message
- Add metadata associated with the source message.
- Assign data ownership - data steward and function
- Manage fields in message
- Edit an existing message
- Delete an unwanted message (soft delete)
Licensing
There are no limits or constraints to the number of source systems that you can have in the Lite version, Pro and Enterprise version.
Maps Module
The Maps Module focuses on helping you prepare and organise all your data for CryspIQ®. It enables you to apply multiple methods and defaults to prepare and organise your data into the universal context.
 Key Benefits:
Key Benefits:- Removes the manual efforts required to discover data.
- Removes the requirement for intepretation of the data.
- Adds contextual metadata to data.
- Provides consistent understanding of terminology used.
- Provides traceability and lineage back to source record.
- Manage a library of maps for source messages to the CryspIQ®.
- Re-use an existing map and adjust it to fit your requirements.
- Build your own map and add it to the global library.
- Apply customised methods and defaults to your data.
Manage Maps
Manage your organisation mappings for each source message:
- Create new mapping, and add methods and defaults where required.
- Capture linkkey field for traceability back to source record.
- Add search metadata, to assist users to find what they're looking for.
- Update existing mapping,
- Add / edit / delete methods
- Add / edit / delete defaults where required.
- Delete existing mapping(s)
Methods
Manage the rules / logic / methods that can be applied to each mapping at a field level:
- Create new method
- Update existing method
- Delete existing method
Defaults
Manage the Defaults that can be applied to each mapping at a field level:
- Create new defaults
- Update existing defaults
- Delete existing defaults
Licensing
There are no limits on the number of maps that can be created in the Lite version, Pro and Enterprise version.
Data Quality Module
The Data Quality Module focuses on supporting your data governance journey and ensuring that all data provided conforms to the required level of quality criteria.
 Key Benefits:
Key Benefits:- Insights require reliable contextual data.
- Visualise the quality of data being provided.
- Build trust and reliance on your data.
- Provides the foundation for informed decision-making.
- Parking Lot
- Functional dashboards.
- Steward dashboards.
- Setting data quality Rules.
- Data quality notifications.
- External API methods.
Parking Lot
When Data is processed through the mapping engine contextual metadata is added as it goes through processing. However there are instances where the contextual metadata not available and thus the data records land in the ParkingLot and wait for the missing data to be loaded. Contextual metadata is required to turn raw data into information that is useful. Records remain in the parking lot until the missing contextual metadata is loaded. There is a self healing mechanism in place which releases records from the parking lot once the missing data is loaded. Users can click on the relevant data type to see what contextual metadata is missing for the type. Users also have the ability to export data from the Parking Lot to csv and interrogate further.
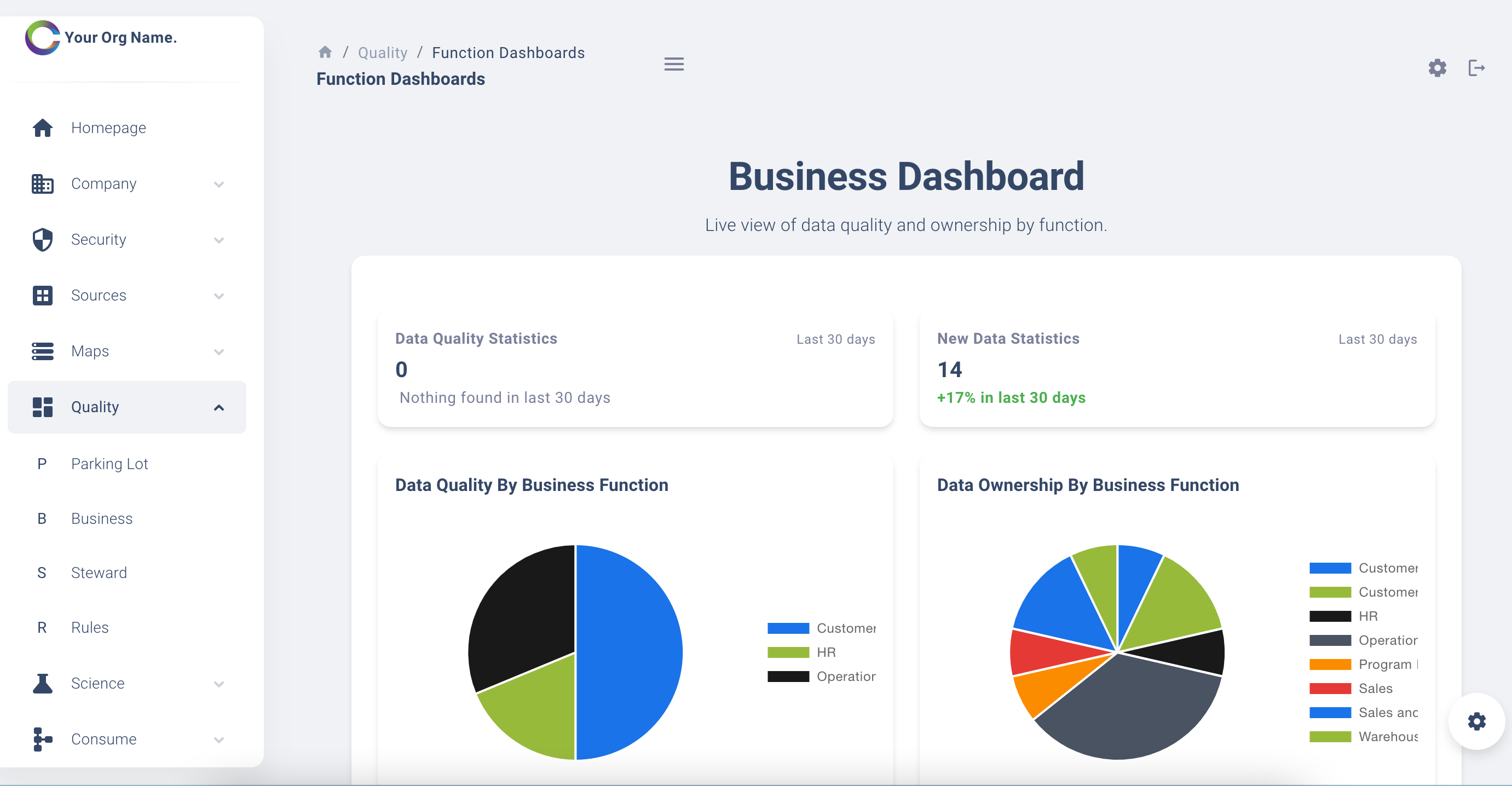
Function Dashboards
A dashboard with drill through capability that assists the data owner to understand data quality issues identified for their organisational function. The dashboard is live and can be viewed across the organisation, thus all parts of the organisation will be discussing things from a single source. For large organisations, this allows data quality to measured and good data governance processes to be implemented to avoid re-currence.
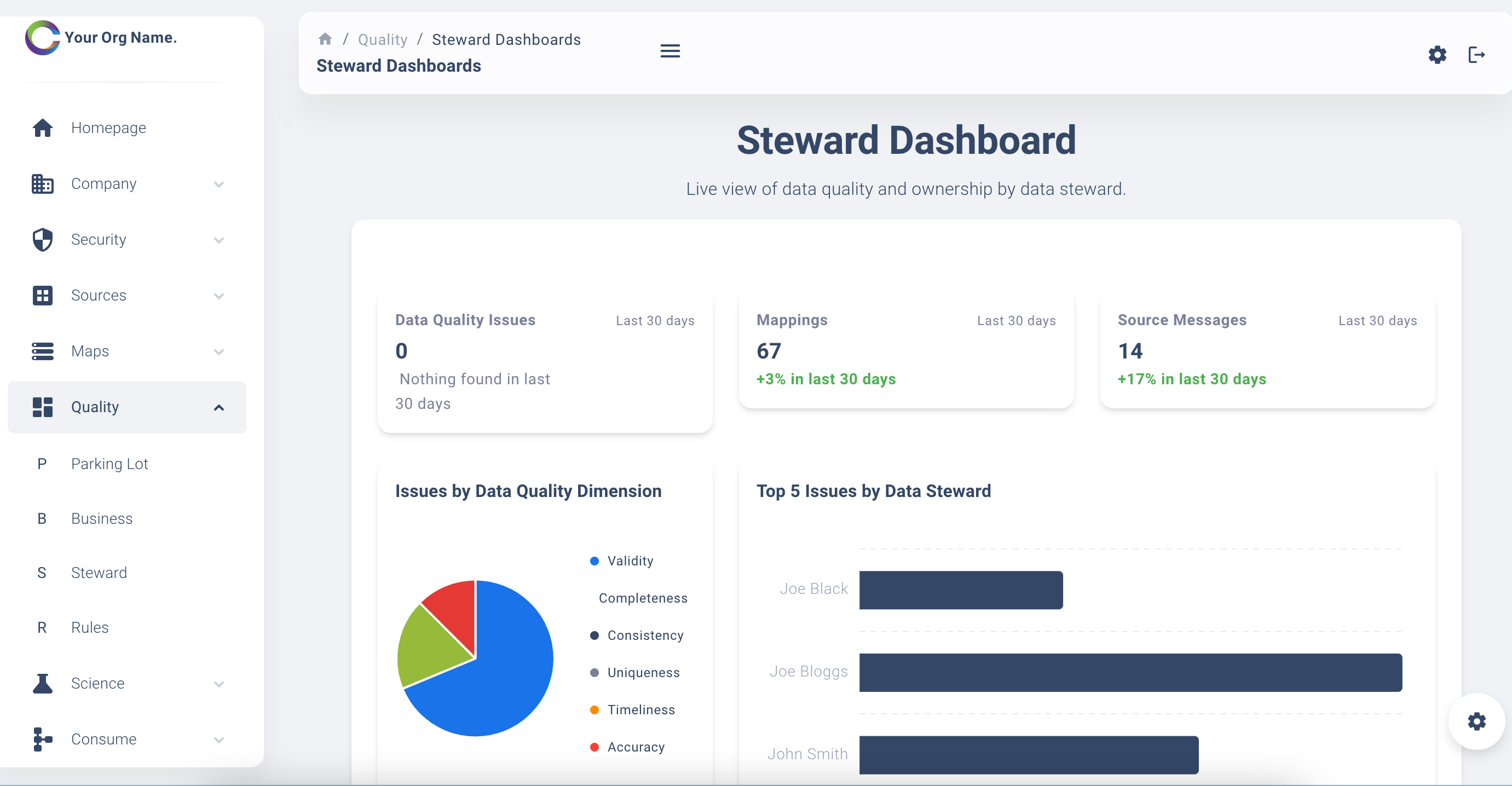
Steward Dashboards
A dashboard with drill through capability that assists the data steward to understand data quality issues identified. The data steward is responsible to ensure that the issues identified are fixed at source and records re-submitted. It's a live dashboard, so the data quality issues will remain in place until they are resolved.
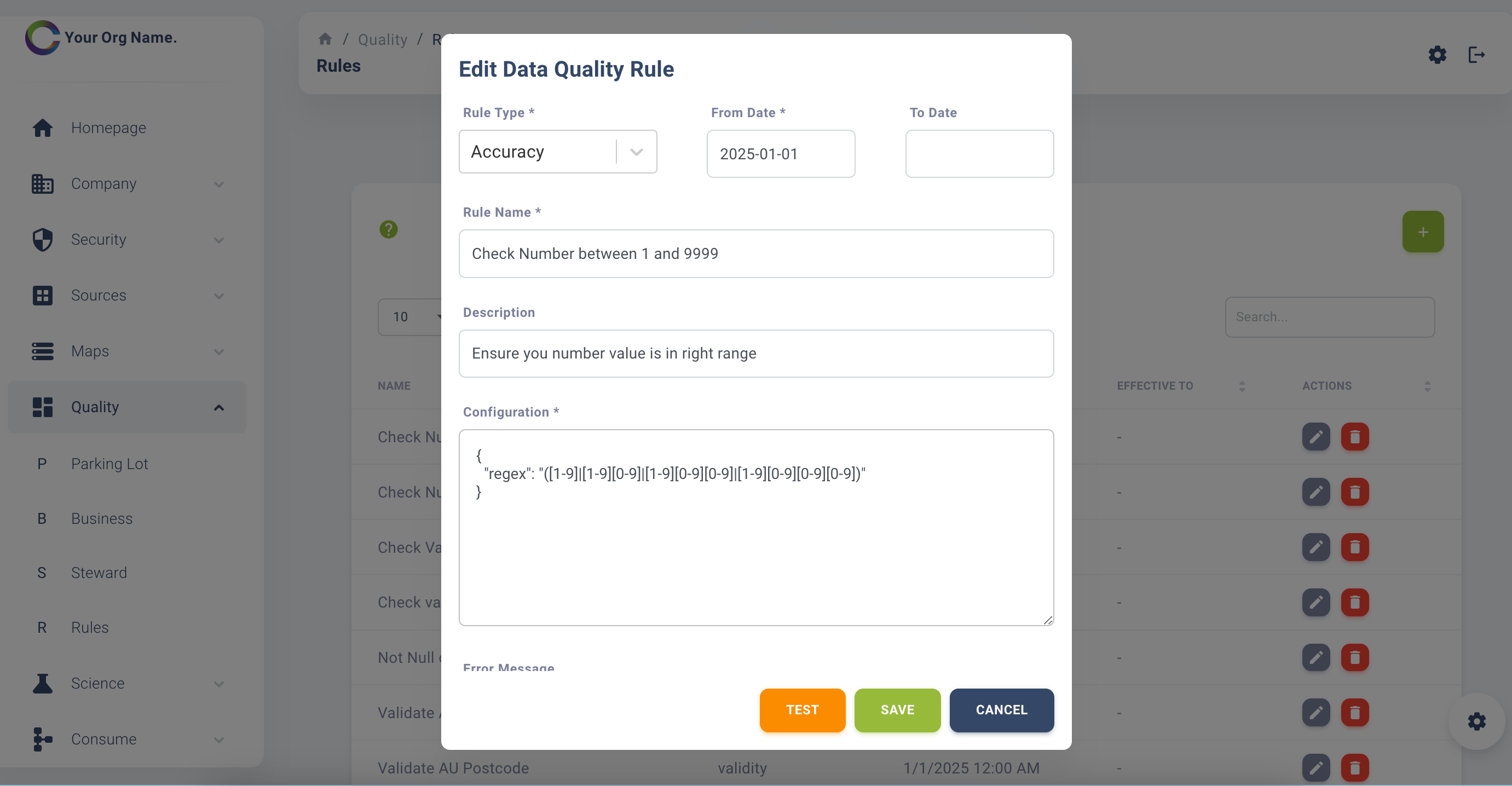
Rules
Build you data quality rules / methods that will be applied to the data as it arrives. The rules are categorised / flagged according to the data quality dimension that they fall under according to the DAMA framework. This categorisation is done during the inital set up of the rules. You use regex logic or python programming when building the rules. An example is shown below:
Notifications
Configure data quality notifications to be sent the data steward, when new issues are identified.
External API methods
Use external application programming interfaces (API) to validate the quality of you organisation Data. API method rules need to be categorised / flagged according to the data quality dimension that they fall under according to the DAMA framework. This is done during the set up of the external api connection.
Licensing
The dashboards, local data quality rules and notifications are available in the Pro. and Enterprise version. The external API methods are only available in the enterprise version.
Consume Module
The Consume Module focuses are simplfying how your users find, use and access the data they require. This module caters for both types of users (technical vs non-technical) depending on their preference.
 Key Benefits:
Key Benefits:- Data is ready for use once it has been loaded.
- Ask questions of your data using everyday language.
- Have a two-way conversation with your data.
- No technical knowledge is required.
- Natural language query model (Text to SQL).
- Build your own SQL queries.
- Existing query library.
- Enabling scenario notifications.
- Application to application communication.
Data Glossary
Users can click on the relevant data type that they are interested in. The types will be filtered down to that specific type in the Grid View. Provides the ability for a user to search and see what types of data are available.
There is also a section called "All Data Available".
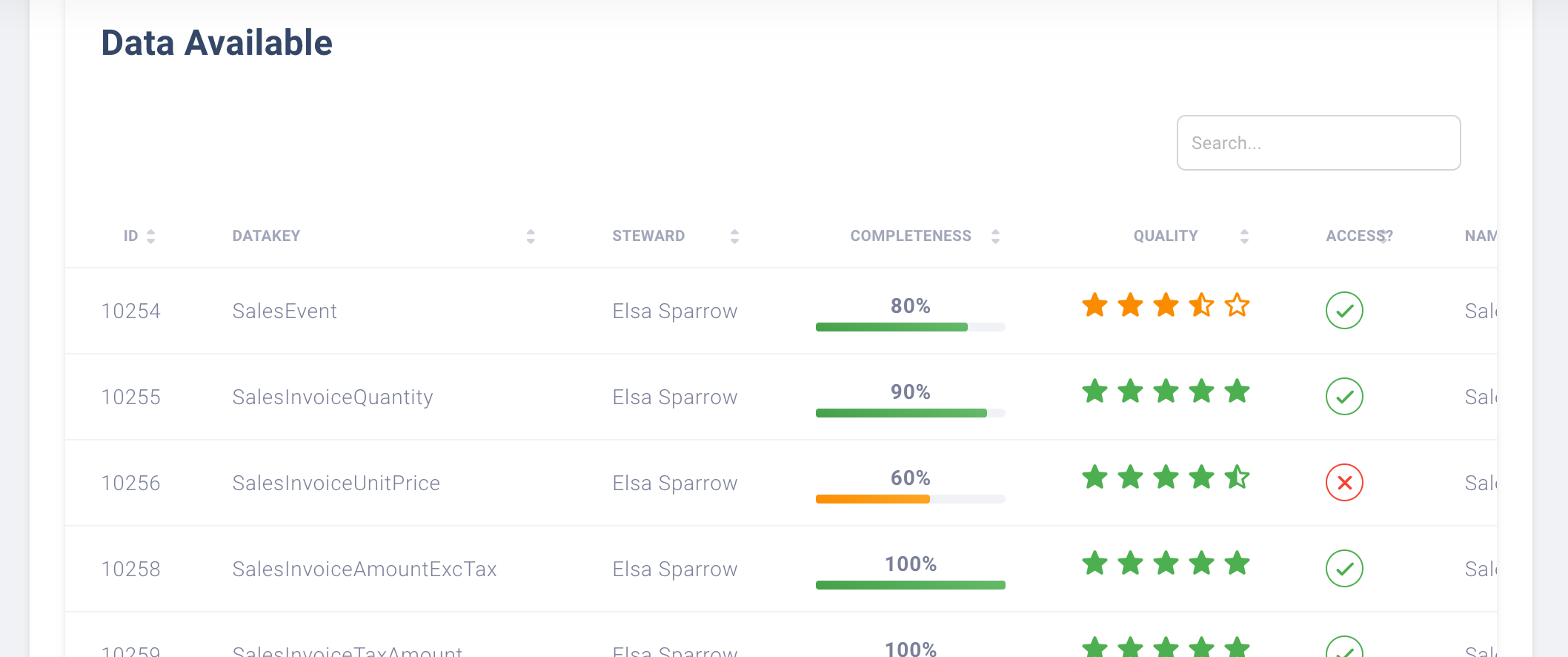
This shows the following to the user:
- Access - does logged in user have access to this Fact record? "Yes" = tick and "No" = cross. Access required contact the steward.
- Steward - identifies the person to contact if there are ay queries around that specific piece of Data.
- Completeness - shows if the Data has all the required contextual metadata associated to it or highlights completeness of this activity. Percentage is calculated based on records in the ParkingLot.
- Quality Ratings are calculated based on the following:
- if there are < 5 Data Quality records for that DataKey, the rating score is 4.5 out of 5.
- if there are between 6 - 10 Data Quality records for that DataKey, the rating score is 4.0 out of 5.5
- if there are between 11 - 15 Data Quality records for that DataKey, the rating score is 3.5 out of 5.
- if there are between 16 - 20 Data Quality records for that DataKey, the rating score is 3.0 out of 5.
- if there are between 21 - 25 Data Quality records for that DataKey, the rating score is 2.5 out of 5.
- if there are between 26 - 30 Data Quality records for that DataKey, the rating score is 2.0 out of 5.
- if there are between 31 - 35 Data Quality records for that DataKey, the rating score is 1.5 out of 5.
- if there are between 36 - 40 Data Quality records for that DataKey, the rating score is 1.0 out of 5.
- if there are > 40 Data Quality records for that DataKey, the rating score is 0 out of 5.
Query Library
You are provided with the query library which contains pre-built queries which can be re-run by anyone across your organisation. Security will be applied on the results returned, so people will only see what they are allowed to see.
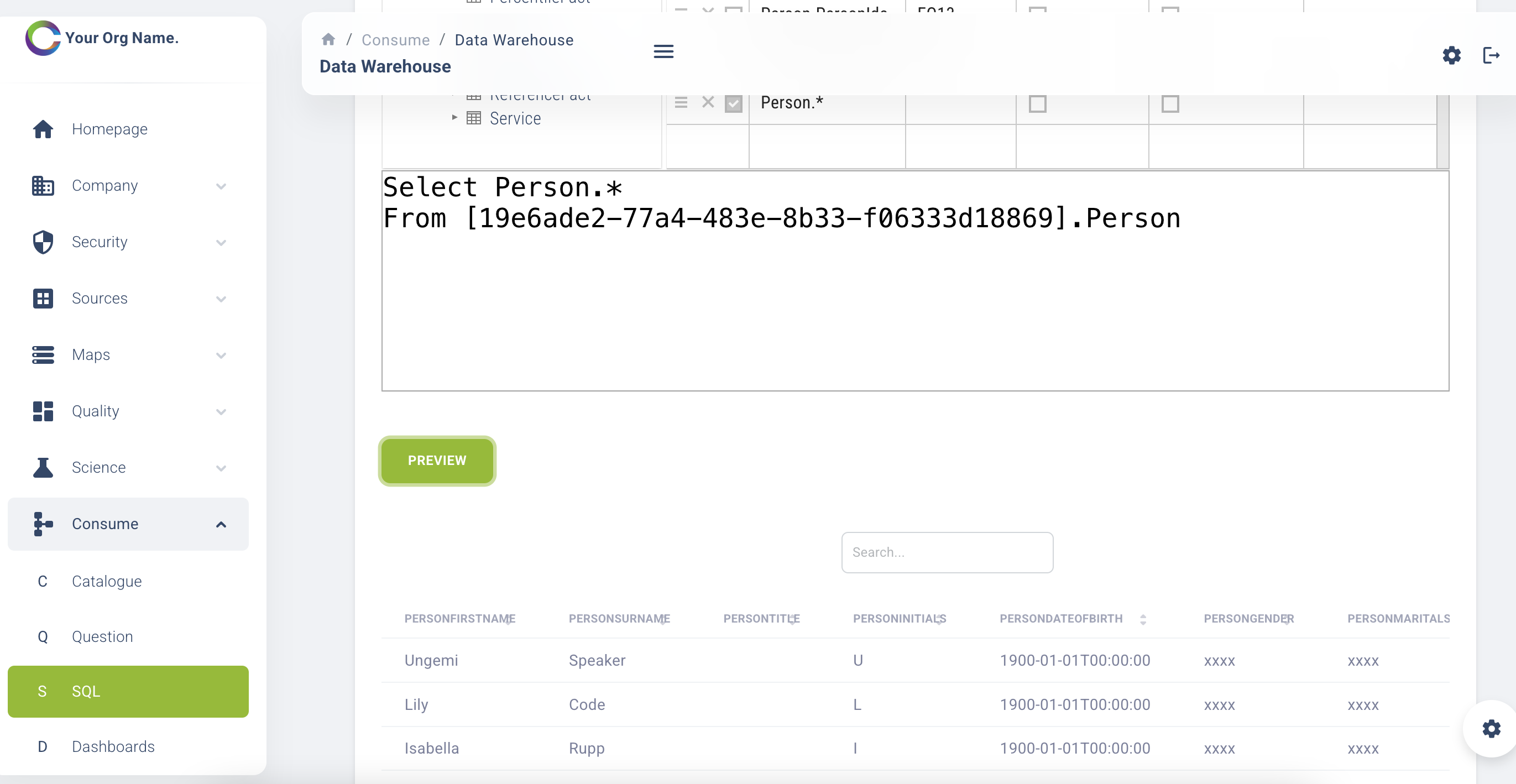
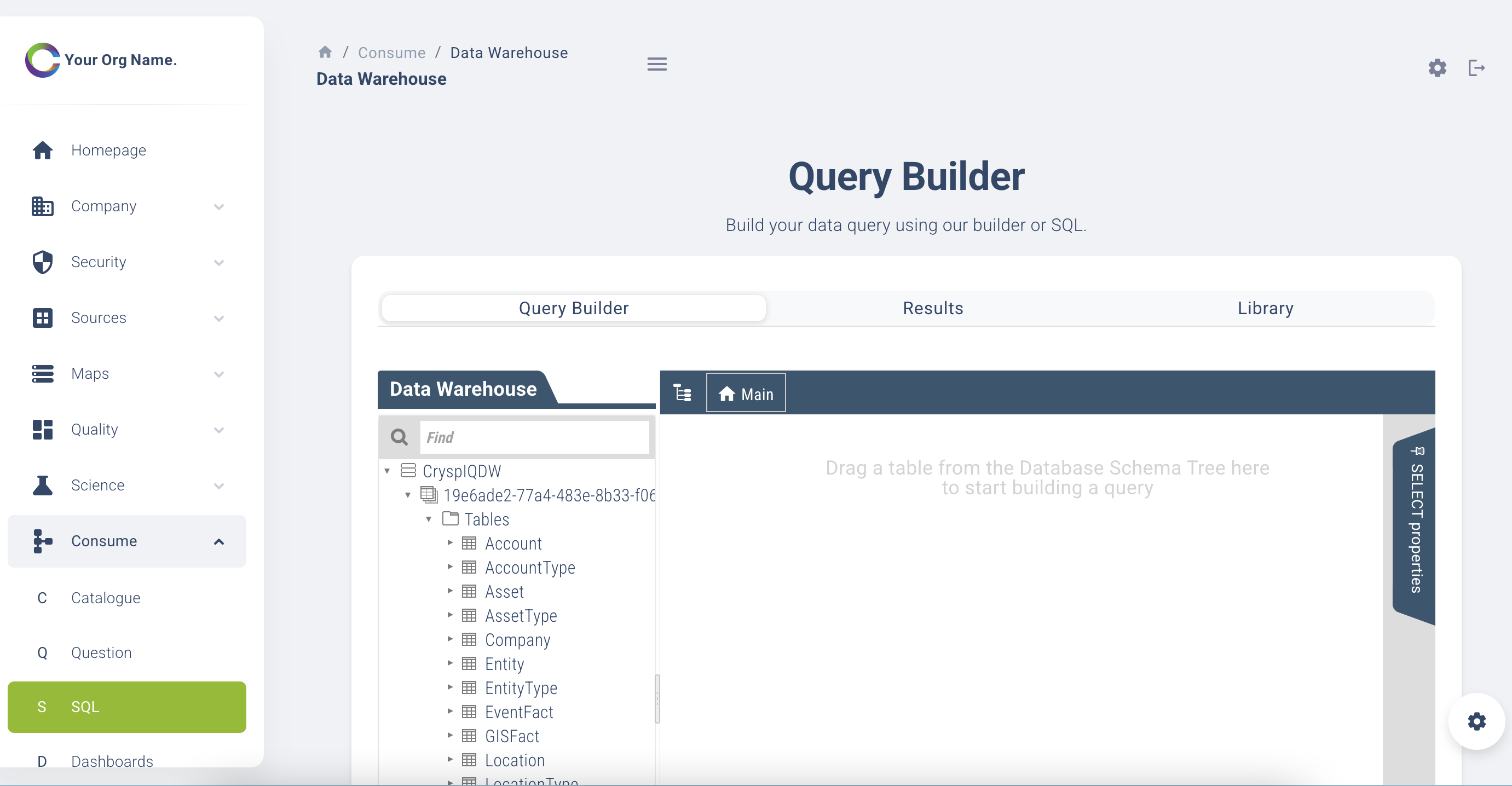
Query Builder
You also have the ability to build your own query and add it to the organisation library for others to use. You have the ability to re-use an existing query, tweak it to fit your requirements and then save it as new query in the library.
Some features of the query builder are:
- Drag and drop functionality query builder by selecting your facts and the data required.
- Preview the query outputs
- Text box for standard Structured Query Language (SQL)
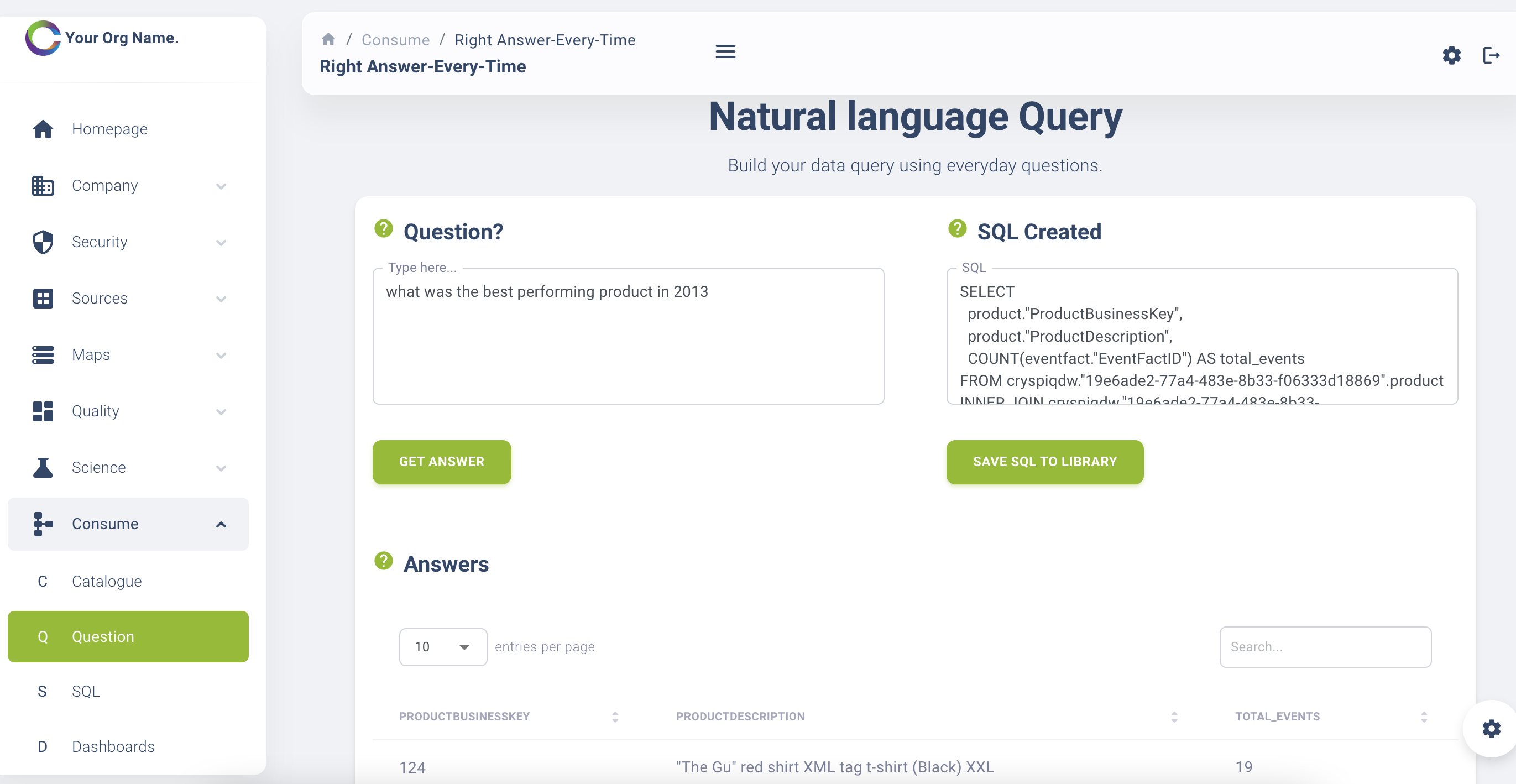
Natural Language Query
This functionality will leverage the natural language query model libraries to use human language to build the SQL queries required to provide your results. See it in action:
Scenerio Triggers
Build conditional / scenario-based data triggers to drive your organisation with Data from production control systems (OT) and other technologies (IT). Query data from production control systems (Operational Technologies) and other technologies (Information Technology) in the same way in CryspIQ®. Use these queries to investigate difference possible solution scenarios and build triggers to drive your organisation forward.
Application to Application Calls
Build applications which utilise the CryspIQ® Data as the single source of truth for the organisation. Use triggers and organisation scenarios to drive automation down stream organisation processes. Set up connections to CryspIQ® using Rest or Webhooks functionality.
Licensing
The query Library, query builder and natural language query features are available in the Lite, Pro and Enterprise versions. The scenario triggers and application to application features are only available in the Enterprise version.